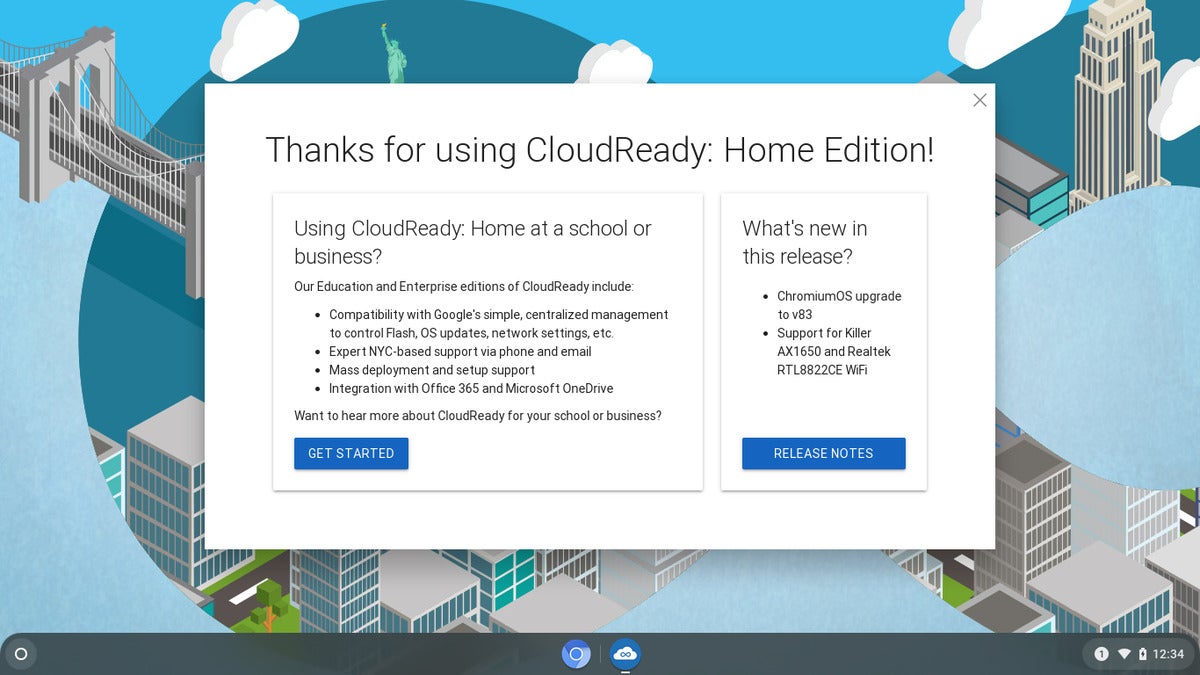
For my son’s virtual classroom, most of his work is being done using Google’s cloud services. I’ve decided to take an old T420 laptop that was in the basement and turn it into a Chromebook for him to use. So far it’s going ok.
If you are interested in doing something similar, I found this article on PC World very detailed and good for all skill levels. (I’ve read a half dozen pieces and the ones I reviewed all pretty much said the same things.) All you will need is an old PC (or maybe an old Mac), a 16 GB USB stick, and some patience. 🙂
I haven’t wiped the Windows OS yet: I booted up the 420 and told it to load the OS from the USB stick. (This part will differ from machine to machine.) With the 420 it’s easy: just hold down the blue button on top of the keyboard and let it go into setup mode and then follow the prompts.
I can’t say that the user experience is fast. It’s….not terrible. Still slow. But once things come up, it should be good.
More from me as new results come in.
Oct 19: so far so good with the Chromebooks. I ended up wiping the old OS and installing the ChromeOS on the disk drive. One odd thing: there is no notification that the installation is complete. So I recommend you start it, leave it for 30 minutes or so, then reboot the laptop. It should come up with the new OS.
One nice thing about it is that my son has Chrome settings (e.g. bookmarks) specific to his Gmail account. So when he logs into the Chromebook, I can set up the bookmarks specifically for his e-learning (e.g., I have links to all his courses on the bookmark).
The other thing I like about converting old laptops into Chromebooks is that the screen and keyboard is often better than most Chromebooks. For example, I turned a T450 into a Chromebook and I love typing on it.
Finally, old laptops are relatively cheap. You can get T420 for under $300, and T450s for around $350, which is cheaper than many (though not all Chromebooks). Better still, I bet many people have an old PC lying around doing nothing. Make it into a Chromebook and give it to someone who could use it.
Dec 28: It looks like Google bought the company that made the software I used. I am not sure what this means, but one thing it could means is that Google shuts it down. If you were thinking of doing this, best do it sooner than later.


 Food bloggers are seeing a drop in traffic as home cooks turn to AI, according to
Food bloggers are seeing a drop in traffic as home cooks turn to AI, according to  I was recently surprised to learn of a great way to learn more about the arts: Google.
I was recently surprised to learn of a great way to learn more about the arts: Google. IF you are a fan of using Chrome to cast one of your tabs to a TV, you may be surprised to find that the Cast option is missing. Worse, if you look in places like
IF you are a fan of using Chrome to cast one of your tabs to a TV, you may be surprised to find that the Cast option is missing. Worse, if you look in places like 



 I wrote some time ago about how I
I wrote some time ago about how I 




:format(webp)/cdn.vox-cdn.com/uploads/chorus_image/image/66145941/Screen_Shot_2020_01_22_at_3.51.22_PM.0.png)






