Well before the end of 2014, I had decided that I was no longer going to participate or contribute to anything outrageous or political on social media generally, and twitter in particular.
This week I let down my guard and did participate and comment on the recent events in France, mainly because I was stunned by the act of violence.
After considering it for over a week, I think that was a mistake and I am writing this partially to insure I don’t make that mistake again. If you are curious, the next few lines explain my thinking around that resolution. The last four paragraphs talk about what I am going to do instead: feel free to skip down to there.
I have been using social media for a long time, relatively speaking. At first it was merely a curious experience. Then it went to being a positive experience. But more and more it has become a negative experience.
Once social media, and twitter in particular, was for people sharing status. It was random: some good, some bad, nothing focused. However, one really good thing about it was that you got to know people. People you might never get to meet before: the famous and the fabulous and the funny and the friendly. It was a great experience. I know from my own experience that my life was greatly improved by this greater network that I got access to.
While my feed of updates was once rather random, over time people started focusing their use of it. Celebrities used to to promote their work. Politicians did too. Activists started to try and rally people to their cause. Artists tried to make it into a new form of writing. That was still good.
Among people on twitter, a growing belief was that the benefit of twitter over a site like Facebook was that you could hang out with people you liked but didn’t know (as opposed to hanging out with people on Facebook that you knew but didn’t like). I never agreed with that knock against Facebook, but I did like the people I encountered on twitter. They were good people.
Then not so good people came along. People with no other interest in twitter and social media than to cause problems. It was like a pile of aggressive drunks showing up at a party and getting into fist fights with the rest. Twitter, the company, seem to have no plan in dealing with this. Perhaps it was a result of this, or perhaps it was something else, but the level of aggressiveness and negativity rose on twitter as well. It was a variation of Gresham’s Law, where instead of the bad money driving out the good, the antisocial behavior drives out the positive social behavior. Whatever it is, what I found was that the amount of positive sharing seemed to diminish. People tended to communicate with people they had a previous relationship with, and people seemed more likely to share negative things.
I believe as a result of that, we now see these ever increasing outrage storms on twitter. Where once the outrage over events of the day — if you had any at all — would be limited to yourself or your small social circle, now you can share it with hundreds or thousands of people. Those people can take that and share it with the people they know. And then to add to that, there will be people who disagree with you, and they will express their displeasure to you directly in a way they never could or would if you knew them personally. This all adds up to an enormous cloud of negativity.
Last December, I noticed people saying 2014 was a terrible year. That surprised me. I am older than many people on twitter, but most people on twitter are educated and experienced enough to know that relatively speaking, 2014 was not a particularly terrible year for many people in the world. I could think of many years in recent memory that were much worse economically, that had much more violence, that had much more disease and suffering. There were terrible things that happened in 2014, but terrible things happen every year and 2014 was no exception.
I believe that people thought 2014 was a terrible year because all of the feedback that they constantly get that gives a strong impression that it was terrible. And feedback is the right word. More and more of the things shared on twitter are negative. Either they are personally negative or there is something in the world that we see which is terrible.
I used to think that sharing such information on twitter could make a positive difference, and that by sharing such information, even if it is upsetting, then it was worth it if something good could come from it. I no longer believe that. Topics change so frequently on twitter now that it is easy to miss them if you are not on twitter for a few days.
Instead, I find social media to be more and more upsetting and aggravating with little upside. There are times when people need to be upset and aggravated if it helps them achieve something they want but can’t achieve otherwise. But too much “stick” and not enough “carrot” is just a form of voluntary suffering.
There have been many times when I wanted to give up on twitter. Back in the fail whale days, the lack of availability was frustrating. Then I was angry when twitter started taking over my stream. In both cases there were technical workarounds to those problems. But this is a social and a culture problem, and those are hard if not impossible to fix with technology.
Ultimately I could give up on twitter. But I have come to like a lot of the people on twitter I follow, and I would hate to lose track of them and what they are doing. It would be nice if there were better ways to filter and manage the information that shows up in my feed, but Twitter the company seems to have decided it is not in their interest for me to do that.
Given all that, my own remedy is slight. The one thing I can do is try and change my own contribution to twitter and try to focus on contributing more constructive and positive updates. I’d encourage you to do the same. Enough positivity and constructive updates can make a big difference eventually.
Also, I am going to try and spend less time vegetating in front of twitter much the way other people crash and vegetate in front of TV. I actually read every tweet in my feed. (Hey, the people I follow in India and Australia and Germany tweet later so I have to read it all:)). Instead of vegetativing like that, I hope to spend my time reading more books, making things (from bread to furniture) and generally get out and do things. I would encourage you to do that as well.
Finally, I am going to look for a select group of causes I can contribute time and money to and focus on the little I can do with the limited resources I have at my disposal. I think I can have more of a positive effect on the world that way than I can contributing to the latest outrage storm on twitter. I would heartily encourage you to do that as well.
If you have made it to this point, I want to thank you for reading this. You may not agree with it, but I hope you were able to take away from it something positive and worthwhile.

 Last year I wrote that Bluesky is making social media fun again, and that was true. It’s still somewhat true: of the remaining platforms, Bluesky and Instagram are still getting steady use from me in 2025.
Last year I wrote that Bluesky is making social media fun again, and that was true. It’s still somewhat true: of the remaining platforms, Bluesky and Instagram are still getting steady use from me in 2025.





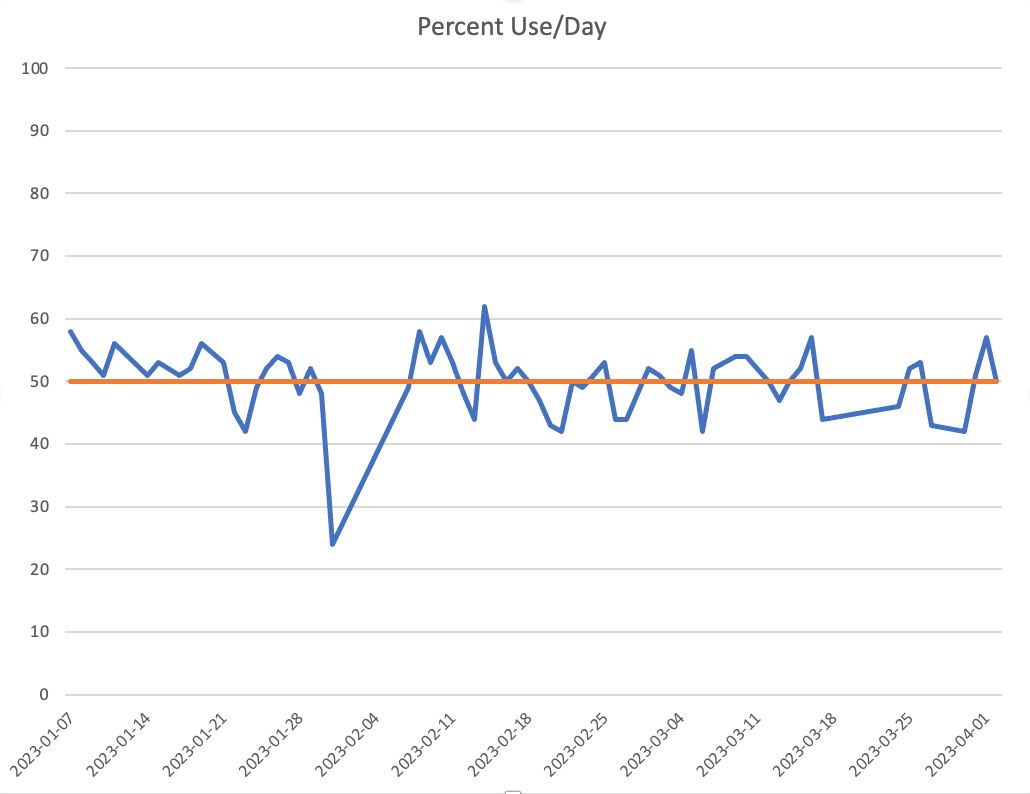
 Like many people, I thought twitter usage was going to decline in 2023 due to all of the shenanigans of Elon Musk. While it seemed like usage was dropping off, I wanted to take some measurements to be certain.
Like many people, I thought twitter usage was going to decline in 2023 due to all of the shenanigans of Elon Musk. While it seemed like usage was dropping off, I wanted to take some measurements to be certain.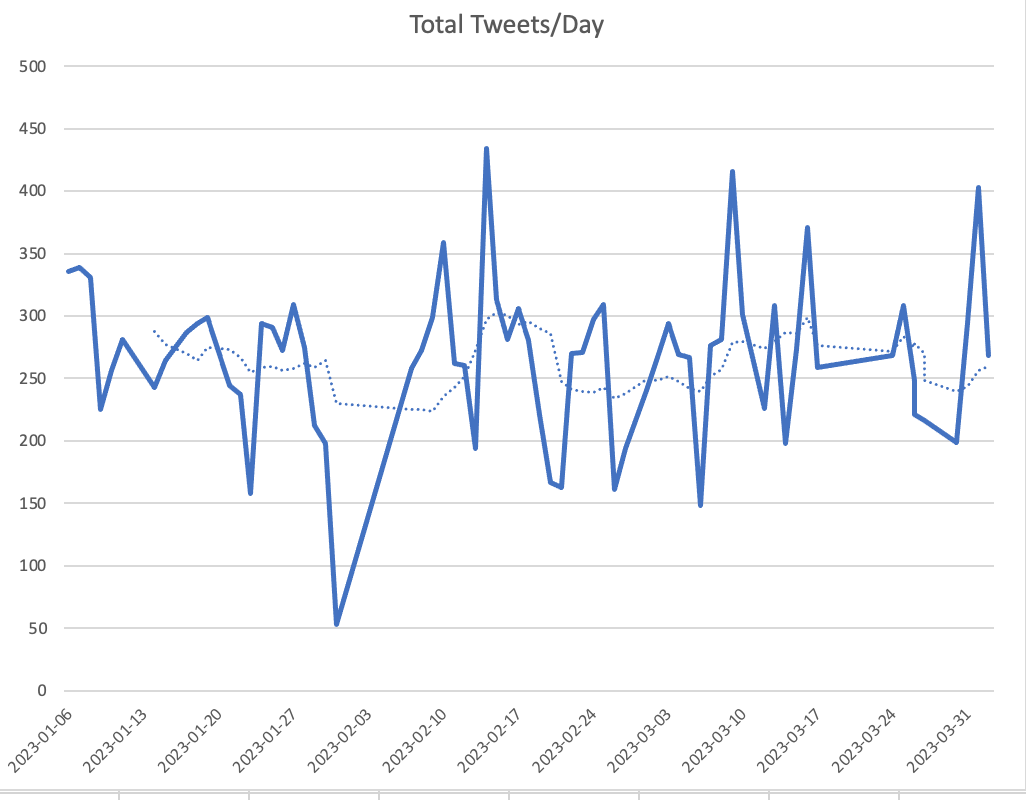

 Long ago, twitter was interesting for many reasons. One reason was people trying to be creative within the 140 character limit. Or to link things seemingly unrelated with hashtags. Weird twitter, as some called it, was good twitter.
Long ago, twitter was interesting for many reasons. One reason was people trying to be creative within the 140 character limit. Or to link things seemingly unrelated with hashtags. Weird twitter, as some called it, was good twitter.



 Generally I think it is a good idea to keep it positive and light on twitter. I especially try and avoid political tweets. However, I found that hard to do this week. To stop myself, I kept a log of all the things I was going to tweet about but didn’t. The following is the log.
Generally I think it is a good idea to keep it positive and light on twitter. I especially try and avoid political tweets. However, I found that hard to do this week. To stop myself, I kept a log of all the things I was going to tweet about but didn’t. The following is the log.



 I have long tried to not get into arguments with people on the Internet*. This has served me well. If you are struggling with that, I recommend this piece:
I have long tried to not get into arguments with people on the Internet*. This has served me well. If you are struggling with that, I recommend this piece:
:format(webp)/cdn.vox-cdn.com/uploads/chorus_image/image/66947515/twitter_voice_pano.0.jpg)
 Many years ago I gave up on the notion of having any form of influence using Twitter, either as an individual or as part of a bigger force united by some such thing as a tag. Indeed, I gave up on the idea of using Twitter for anything other than sharing things with the few people who engage with me at all on this site.
Many years ago I gave up on the notion of having any form of influence using Twitter, either as an individual or as part of a bigger force united by some such thing as a tag. Indeed, I gave up on the idea of using Twitter for anything other than sharing things with the few people who engage with me at all on this site.




