

I have been playing the New York Times Crossplay game against the computer in hard mode and most of the times I win. Here’s what I’ve discovered:
- In hard mode the computer “likes” to play longer words whenever possible. Many times these are uncommon words.
- The computer will try and play the 2W and 3W tiles, but it seems to “prefer” to play longer words over shorter words, even if a shorter word on a 2W or 3W might gives more points.
- The computer will stack shorter words but it tends to do that later in the game when it is harder to play longer words. It will stack longer words if it can.
These have been my observations. Give that, to increase my chances of beating the computer, I will:
- hold back letters with higher values unless I can score at least 20 with them on my current turn.
- wait for the computer to set me up for 2W and 3W tiles and then play the higher value tiles. I find it will play a long word to maximize it’s length, even if it is easy for me to stack on top of its word and get the 2W or 3W tile. It doesn’t seem to play defensively.
- My expectation is the computer will do this at least 2 or 3 times a game, so being patient even when I am down is key to beating the computer.
- if I can’t do anything good with an open 2W or 3W, I will take it if there is a chance the computer can reach it in 5 tiles.
- I will set myself up for a 2W or 3W in the next move by holding back a tile. Let’s say I can end a word in S, but it means it is possible for the computer to use that S to play a word and to get to a 2W or 3W tile. If I was playing a person, I might be worried they were going to get that in the next round. But if there are open spots on the board where the computer can play a longer word, chance are it will go for the longer word instead, so in the next turn I can lay down the S and hopefully spell out a word to get the 2W or 3W tile.
I say most of the time I will beat the computer in hard mode. Crossplay is a game of chance as much as anything, and some games I will get a bad assortment of letters and the computer will get a great assortment of letters and I will lose. But by adopting the approach I described above, I can frequently beat the computer in hard mode, even though it knows more words than I do.
P.S. My overall general approach is to always aim for the highest score for each play. Often this means stacking words — even small words like “LI” and “OR” — on top of other words to maximize my score rather than playing long words, the way the computer prefers to do. Stacking words gives less openings for my opponent, which is especially effective against the computer, which will often open up the board by playing a long word.



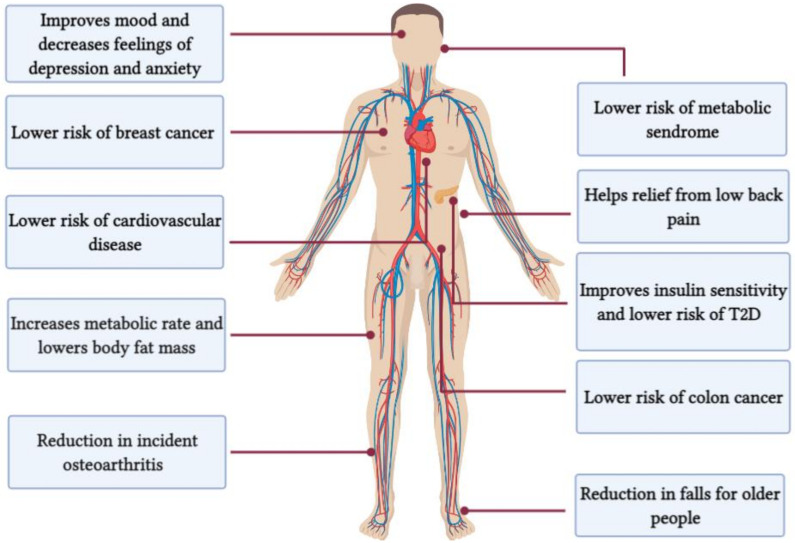 You can find lots of evidence of how HIIT is good for you.
You can find lots of evidence of how HIIT is good for you. 

 What is the New York Times? Based on those who have NYT Derangement Syndrome**, it’s a newspaper that has betrayed its progressive readers by publishing articles and oped pieces that are centrist or even right wing.
What is the New York Times? Based on those who have NYT Derangement Syndrome**, it’s a newspaper that has betrayed its progressive readers by publishing articles and oped pieces that are centrist or even right wing.


 I love the the New York Times, I love Charleston, and I love their 36 hours travel series, so I was keen to read this:
I love the the New York Times, I love Charleston, and I love their 36 hours travel series, so I was keen to read this: 


 I’ve posted before on
I’ve posted before on 









 The New York Times does a great job of telling the story of
The New York Times does a great job of telling the story of 










