

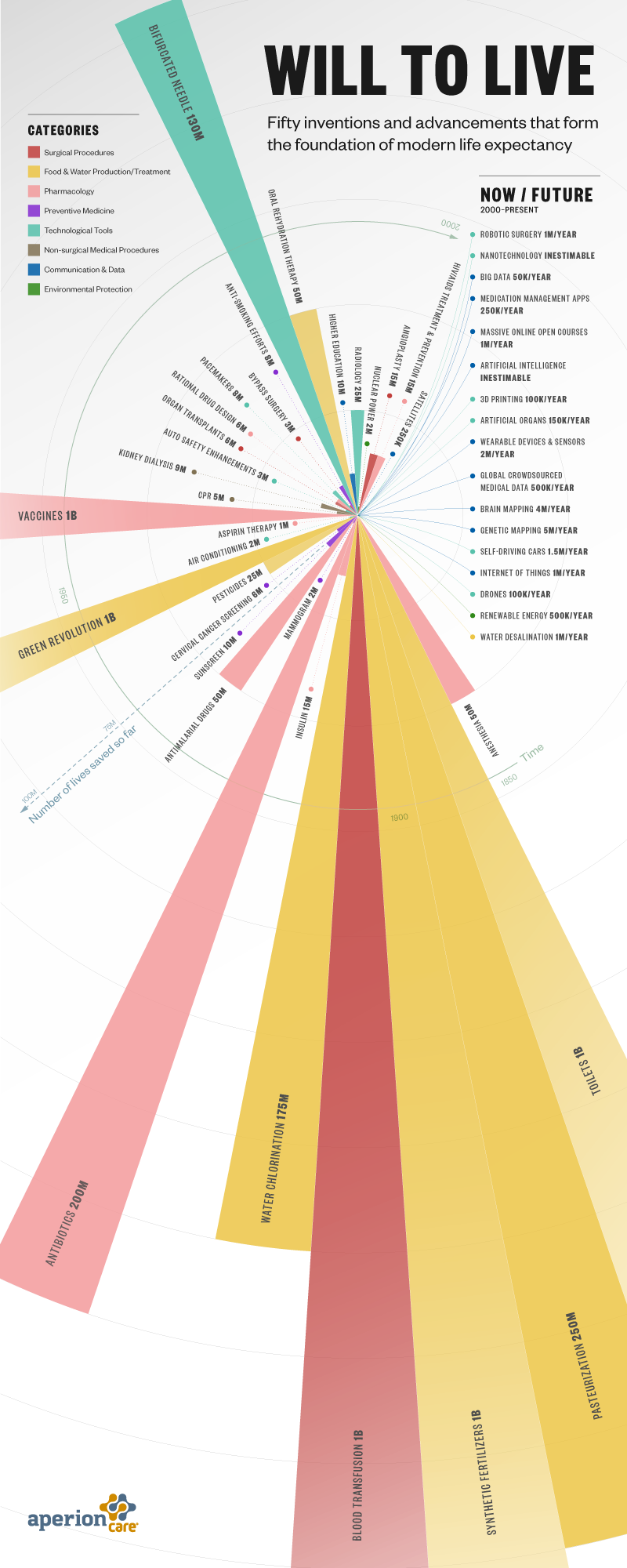
Ok, technically the IBM 604 Electronic Calculating Punch was better than 150 extra engineers. I can’t provide you with one of those, but I can provide you with this list of links on what I find interesting in tech lately (besides AI, which I have posted on separately since it is a big topic in itself).
Hardware
- The big fun thing that came out lately was the MacBook Neo. CNN wrote about it, here: MacBook Neo: Apple launches a cheap new MacBook for the first time and Ars Technica did as well: MacBook Neo hands-on: Apple build quality at a substantially lower price
- More on Apple from Ars Technica: Imminent Apple hardware updates include MacBook Pro, iPads, and iPhone 17e
- Here’s a new laptop worth looking at: Framework Laptop 13 Pro arrives with major redesign, longer battery life, and touch display – Yanko Design. Relatedly, Framework Laptop 13 Pro is the first major revision to the original Framework Laptop – Ars Technica
- Speaking of laptops: The Lightest ThinkPad Ever Also Scored 9/10 for Repairability – Yanko Design
- Here’s some fun hardware stories:
Software:
- I was surprised by this: Why Kubernetes is retiring Ingress NGINX – The New Stack – thenewstack.io
-
I needed this link recently as I was running neo4j in a container: Connect to Neo4j in Docker from python in a different Docker container
- Pardon the language, but this was good: git – the simple guide – no deep shit! Also helpful: Git – Basic Branching and Merging
- This is, frankly, ridiculous: COBOL Is the Asbestos of Programming Languages | WIRED – www.wired.com
- This is neat: Landing Page Templates to Build Landing Pages in Minutes | Rocket Templates – www.rocket.new
- This is a good Linux distro I might try soon: Zorin OS – Make your computer better.

Raspberry Pi :
- Penk makes the coolest computers (see above). Are they practical? Nope. Would I like to take this repo and make one? I would! GitHub – penk/MainboardTerminal: A Retro-style Computer with a Modern Core · GitHub.
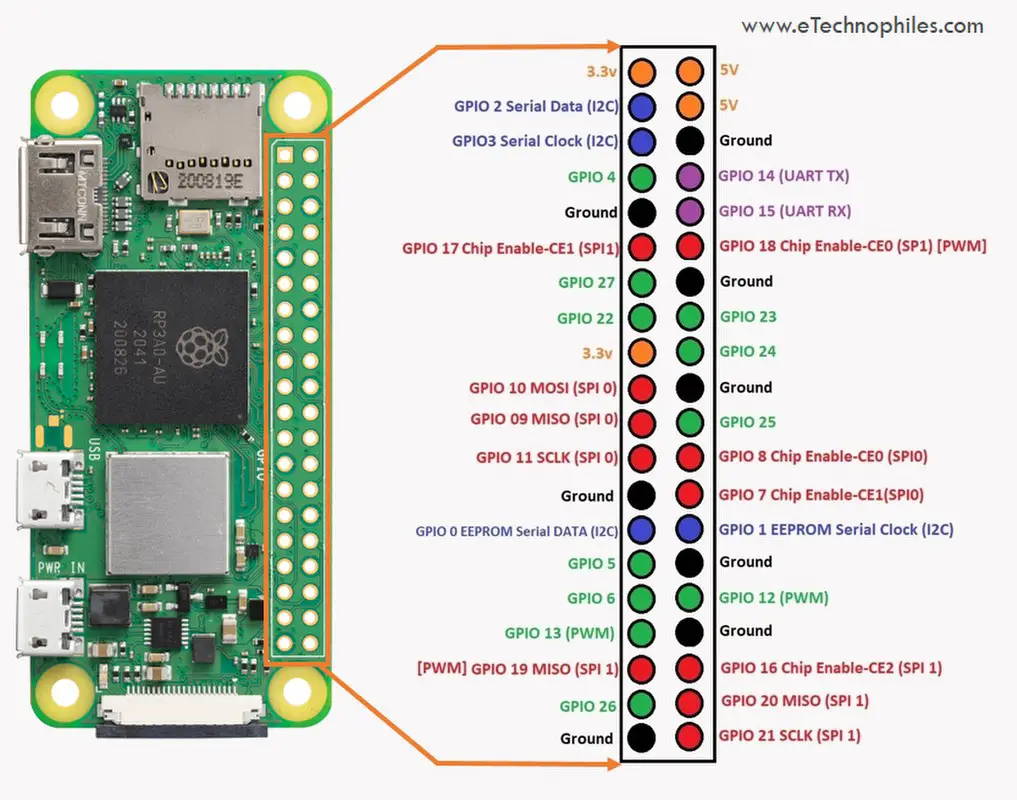
- I was doing some Raspberry Pi work a few months ago. These all came in handy:
Miscellany:
- Not a good idea: I Revived an Old BlackBerry to Cut Down on Screen Time. Things Went Awry. | Reviews by Wirecutter – www.nytimes.com
- I found this useful: Managing Data in IBM Cloud
- Can anything help Apple’s Vision Pro? Maybe this: YouTube is coming to the Apple Vision Pro | The Verge
- A good cheat sheet: Chmod Command Cheat Sheet & Quick Reference – quickref.me
- PROFS was huge in the 80s: PROFS: The Office Suite Of The 1980s | Hackaday – hackaday.com
- I have a number of his covers: Byte magazine artist Robert Tinney, who illustrated the birth of PCs, dies at 78 – Ars Technica – arstechnica.com
- Good to know: Google Now Lets You Change Your Gmail Address. Here’s How | WIRED
- Highly debatable: Tim Cook Was Great for Apple Investors. He Was Not as Great for America.
- Finally, I was watching these IBM commercials with Avery Brooks recently. They are old but still great. Sadly, my favorite one on WebSphere, is not up there, but if you search Youtube you can find these two and more:
(Credit for the top image: File:IBM 150 Extra Engineers 1951.jpg – Wikimedia Commons)






 For a container running in ECS, it is an entirely different beast. You have to:
For a container running in ECS, it is an entirely different beast. You have to:












:format(webp)/cdn.vox-cdn.com/uploads/chorus_asset/file/25234298/Figure_robotics_prototype.jpg)




 AI a year ago was mostly talking about AI. AI today is about what to do with the technology.
AI a year ago was mostly talking about AI. AI today is about what to do with the technology.

 If you are using python packages like xmltodict or yaml to write and read your own XML and yaml files, you probably don’t need to know this. But if you are reading someone else’s files, here is something to be aware of.
If you are using python packages like xmltodict or yaml to write and read your own XML and yaml files, you probably don’t need to know this. But if you are reading someone else’s files, here is something to be aware of.

 Apple is a computing hardware company: if there is a market for a new form of computing hardware out there, Apple will make it. It was true of digital watches, smart speakers, and various forms of headphones. It’s now true of wearable AR/VR devices with the Apple Vision Pro.
Apple is a computing hardware company: if there is a market for a new form of computing hardware out there, Apple will make it. It was true of digital watches, smart speakers, and various forms of headphones. It’s now true of wearable AR/VR devices with the Apple Vision Pro. Wow. I have not posted any tech links since
Wow. I have not posted any tech links since 


 You’ve likely heard of Advent, but have you heard of Advent of Code? Well let the maker of the site,
You’ve likely heard of Advent, but have you heard of Advent of Code? Well let the maker of the site, 
 Now that
Now that  If you are reading this, chances are you cannot write to your USB drive on your Mac.
If you are reading this, chances are you cannot write to your USB drive on your Mac. IF you are a fan of using Chrome to cast one of your tabs to a TV, you may be surprised to find that the Cast option is missing. Worse, if you look in places like
IF you are a fan of using Chrome to cast one of your tabs to a TV, you may be surprised to find that the Cast option is missing. Worse, if you look in places like 
{kind=link}
{kind=link}
{kind=link}