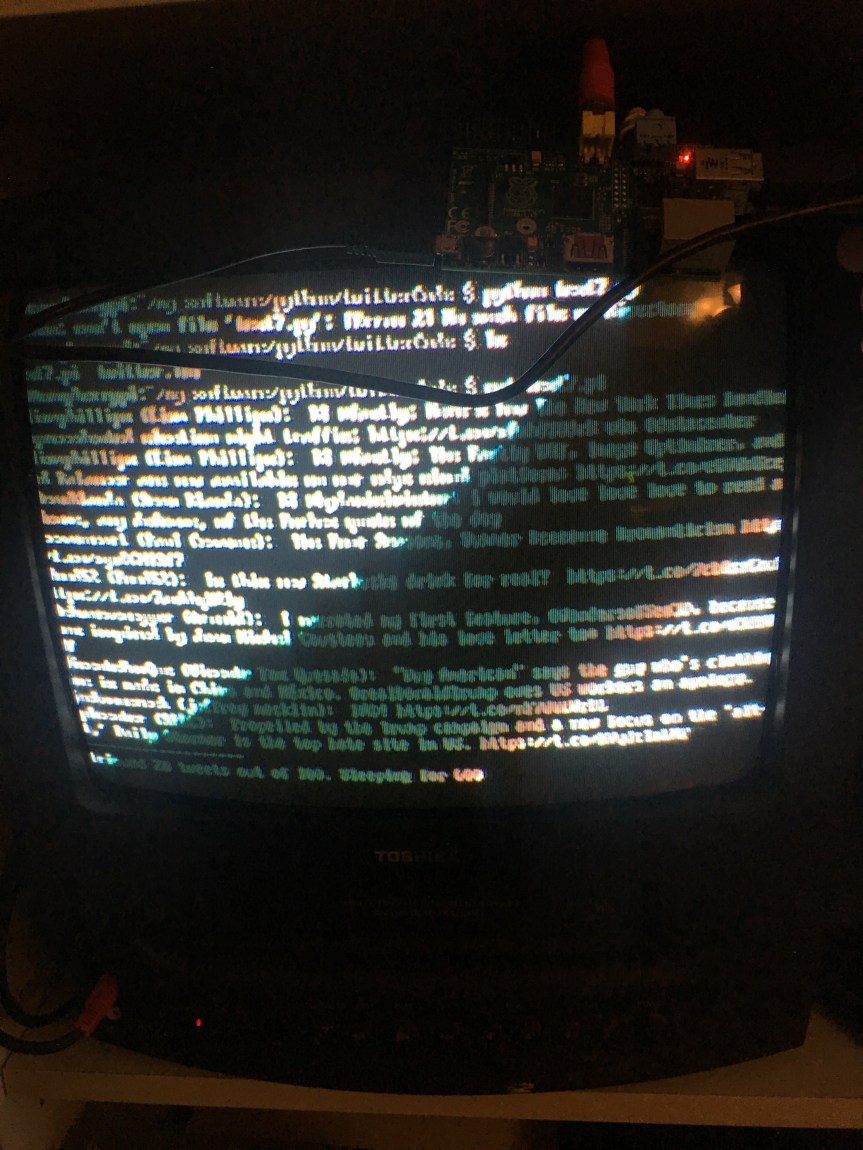
I had an old Raspberry Pi 1 Model A, with an HDMI port and a standard RCA composite video port for older displays and I also had an old Toshiba TV (pictured above) and I wanted to get them working together. Here’s what I did and here’s some things I learned.
First things first, I had to get a the Raspberry Pi functional. To do that, I mostly followed the steps here: http://www.pcworld.com/article/2598363/how-to-set-up-raspberry-pi-the-little-computer-you-can-cook-into-diy-tech-projects.html. I say mostly because I was using a Mac, so I used SDFormatter to format the SD card. If you have a Mac, you can get SDFormatter here.
Basic steps to set up the Pi were:
- Download Raspbian
- Download SDFormatter
- Put the SD Card in my Mac (you want at least an 8 GB SD card).
- Format the SD Card using SDFormatter
- Unzip Raspbian
- Take the files in the unzipped Raspbian folder and copy them onto the SD Card (which should appear on your desktop)
All that is pretty straightforward in terms of setting up the Pi. If you don’t care for the instructions from PCWorld, Google “Raspberry Pi setup Mac” (or Windows or whatever your operating system) and you will likely find a site that is helpful.
Now, once the files are copied on to the SD Card, modify the config.txt file on the SD card. This is a key thing I had to do. Before I did it, I could plug my Pi into the TV but nothing appeared on the screen. After modifying the config.txt file (and it took some hacking around), I was able to get it to work.
Why do you have to do this? It seems that Raspbian assume you will be using HDMI and will not recognize a non-HDMI output device unless you modify the file. So modify it you must.
Note! Before I edited the file and replaced the text in it, I selected all of the text in that file and copied and pasted it into a file on my Mac as a backup. I recommend you do the same. Then I made the changes to the file, saved it, then ejected the SD card and put it in my Raspberry Pi. If you want to see my version of the file, you can see it here.
It was a process of trial and error to figure out which lines in the the config.txt to change. I was fortunate that I could start with this page which had details on how he got it working. Unfortunately his config.txt and the one I needed were slightly different, so I kept at it until I figured out how it should work. (With his file, the text was unstable: it kept rolling up the screen. With my file, the text did not roll.)
In my config.txt, I have colour burst disabled, rendering everything in black and white. Enable it if you want colour. I disabled it because I thought it would improve resolution but it did not.
Other things to note:
- I had trouble determining which part of the composite cable should go into the TV. I had one end plugged into the Raspberry Pi, but it took me trial and error until I figured out where to plug the other end into the TV.
- It will take up to a minute or longer before the Raspberry Pi sends video to my TV. If you don’t see output right away, be patient.
- Most newer TVs also have composite/component ports. I used them for some testing.
- Is it worth doing this if you can hook up to HDMI? I’d say no. I wanted to make use of the old Toshiba TV but if I had an old monitor with an HDMI port, I’d get an HDMI cable from the dollar store and connect up the Raspberry Pi that way.
- When is it worth doing? I’d say if you had simple output to display, and the only ports available on your TV were the component ports, than give it a shot. I actually wrote a simple Twitter client in Python that polls Twitter every 5 minutes and displays my feed in text form. For simple text output like that, this set up is perfect. (You can see the output above: it looks weird due to the refresh rate and my phone: to the eye, it looks ok.)
- Is it component or composite? I see the words “component” and “composite” used and I am not sure which is correct. In my case, all I know is I have one cable to connect the Pi’s video output to the TV’s input port. The Pi has only one video port to plug into, so that’s easy. Most TVs will have more than one port to accept video input: you need to experiment to get the right one.
I hope you found this useful.
P.S. The other thing I like about doing this is: my TV now looks like the TV between Leon and Holden in Blade Runner. 🙂














